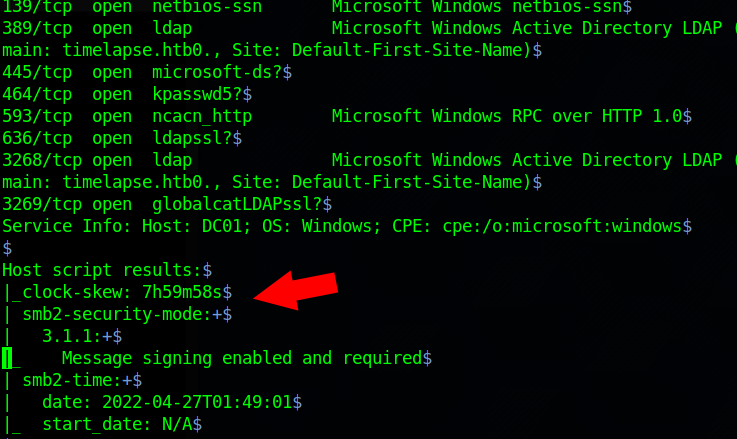
TryHackMe vs. HackTheBox
I wrote a blog article a while back about why I chose HTB over THM. I have to confess something to you. I have had a change of heart. I know. I know. How dare I change my mind!? The team over at THM have been working hard to differentiate themselves from HTB, to the point that in my personal opinion THM has surpassed HTB and HTB is doing some catching up. Just so you know this is all personal opinion stuff. I have used both HTB and THM, so I feel confident in how I feel on the topic. Pros. 1. Simple To Get Started UI is straight forward. Once you have either signed up with a free account or you have decided to pay the affordable monthly fee (more on this later) the main landing page or "Dashboard" is extremely easy to navigate and logical to figure out what to do. In the picture below you can see total users, current rank when the picture was taken, current streak (this picture has 180). Additionally you can see the "Learning Path" where my current activiti